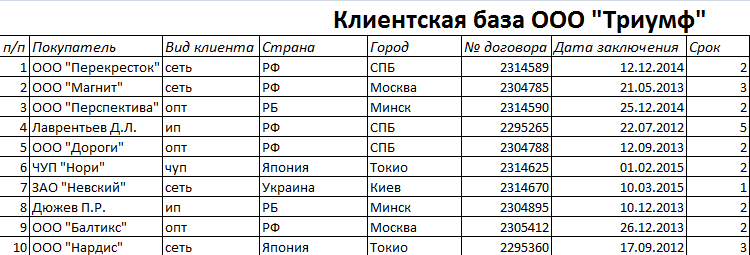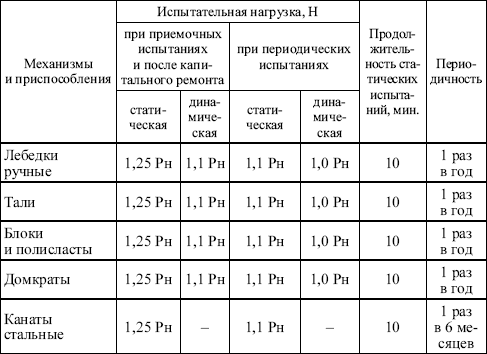





Категория: Бланки/Образцы
Глобальная база данных является той частью базы данных, которая изменяет свое состояние в результате выполнения правил продукций, выбираемая по определенной стратегии из базы знаний системой управления. [1]
Система OPS5 обеспечивает единую глобальную базу данных. называемую рабочей памятью, которая состоит из множества структур константных символов. [2]
На основе информации, поступающей из глобальной базы данных. создается база фактов о текущем состоянии технологического процесса х, содержимое которой сопоставляется с левой частью продукций вида (4.1) из базы знаний. [3]
Характерной особенностью создания базы знаний в виде системы продукций является то, что глобальная база данных содержит множество фактов предметной области, из которых экспертом выбираются факты, играющие, по его мнению, доминирующую роль при принятии решений по управлению. [4]
Модуль управления базой фактов ( МУБФ) обеспечивает прием и обработку информации от множества датчиков ( глобальная база данных ) и передает ее модулю планирования и логического вывода. Результаты вычислений по математической модели также поступают в МУБФ, после обработки в котором они, в свою очередь, также передаются модулю планирования и логического вывода. [5]
В функции интерпретатора входят просмотр элементов левой части правил (4.1) и сравнение их с фактами из глобальной базы данных. В случае их совпадения применяется процедура, определенная в правой части правила. [6]
Ведение системного журнала представляет собой расширение виртуальной ДИАМС-машины, которое позволяет пользователю сохранить историю изменений в глобальных базах данных. Если пользователь предусмотрел использование этой возможности, то данные об изменениях в глобальных массивах автоматически записываются на магнитную ленту. Изменения производятся командами SET, в левой части которых стоит глобальная переменная, и командами - KILL с глобальными аргументами. Если системный журнал ведется, каждое такое изменение записывается на магнитной ленте. [7]
Область дисковой памяти для работы СПД должна быть предварительно выделена системной программой SPDALL и может быть освобождена для глобальной базы данных программой SPDREMOV. Дисковая память вне этой области для СПД недоступна. Область СПД и область глобальных данных и программ никогда не могут пересекаться. [8]
В 1997 г. в соответствии с Соглашением между Госкомэкологии России и Программой ООН по окружающей среде создан Российский центр глобальной базы данных о ресурсах ( ГРИД-Москва) на базе ФЦГС. [9]
Итак, основные специфические особенности предложенной экспертной оболочки для автоматизированных систем управления технологическими процессами газопромысловых объектов газоконденсатного месторождения заключаются в следующем: в качестве глобальной базы данных продукционной системы выступают данные от множества датчиков, установленных на управляемом объекте, показания которых динамически меняются после каждого активного воздействия на исполнительные органы; экспертная оболочка является управляющей, т.е. вырабатываемые управляющие воздействия в результате логического вывода непосредственно передаются к объекту управления и переводят его в новое желаемое состояние для достижения конечной цели всей системы; для принятия решений по управлению используются также результаты вычислений по математической модели объекта. [10]
Как известно, в продукционных системах цели отдельных действий определяются на основе информации, поступающей от объекта управления. Эта информация рассматривается как динамическая глобальная база данных. [11]
Что делать производителям, которым необходима информация о деятельности их конкурентов в Швеции или Сингапуре. Благодаря последним технологическим достижениям компания может получить точную и своевременную информацию, записанную на CD-ROM, и с помощью таких служб, как America Online и CompuServe. Сегодня производители пользуются следующими глобальными базами данных. [12]
Правила в системе ROSIE организованы в виде множеств, определенных как процедуры, генераторы или предикаты. Генераторы возвращают значения любых видов, предикаты же определяют истинность высказываний. Множества правил работают на глобальной базе данных. но могут создавать собственные временные базы данных во время работы. [13]
Комплекты правил в ROSIE представляют собой аналог процедурных знаний. Один из способов использования комплекта правил похож на вызов условных процедур в обычном английском. Например, выражение Иди предупреди Джона об опасности инициирует вызов процедуры предупреди с двумя аргументами - Джон и объектом, который в настоящее время называется опасностью. При запуске процедуры доступна локальная база данных с возможностью наследования свойств из глобальной базы данных. [14]
Эти две системы сильно отличаются друг от друга. ROSIE с ее англоподобным синтаксисом существенно облегчает проблему представления по сравнению с системой OPS5, имеющей Лисп-подобный синтаксис. Однако OPS5 обеспечивает большую гибкость управления, чем ROSIE, а это облегчает динамическое исправление правил. Модели, разработанные с помощью систем OPS5 и ROSIE, практически решали только задачу локализации источника утечки, используя для поиска сложные эвристики, чтобы исключить те участки дренажной сети, которые наименее вероятно содержат источник. В обеих моделях имелось довольно много подпрограмм, связанных с вводом / выводом, чего не требовали системы EMYCIN, KAS и EXPERT. Пользователь взаимодействовал с системой OPS5 традиционным образом ( группа OPS5 могла бы реализовать в модели асинхронный ввод / вывод тем же способом, что и в системе ROSIE, если бы имелось достаточно времени), в то время как модель ROSIE моделировала асинхронную обработку вопросов и ответов. Обе модели легко справлялись с параллельной обработкой целей ( в действительности происходила обработка вначале вширь), для чего модель OPS5 использовала механизм целевого прерывания, а модель ROSIE - связь наборов правил через внутренние текущие отчеты, посылаемые в глобальную базу данных. [15]
Страницы: 1
Поделиться ссылкой:


















1. Определение понятия «система управления базой данных» (СУБД). Основные определения и термины: предметная область, таблица, объект (сущность), атрибут (поле), экземпляр (запись) объекта, ключ, словарь базы данных. Администрация базы данных (АБД) и основные функции АБД.
База данных (БД) – совокупность взаимосвязанных файлов.
Система управления базой данных (СУБД) – комплекс программных средств, предназначенный для создания, ведения и использования БД.
По возможностям выделяют две группы СУБД:
Полнофункциональные СУБД – наиболее мощные, многопользовательские, с системами защиты, копирования и восстановления данных (Oracle, Microsoft SQL Server), но более сложные СУБД.
Персональные СУБД – с ограниченными возможностями, но более простые в использовании (Access,VisualFoxPro).
Это деление довольно условно, так как персональные СУБД постоянно совершенствуются, догоняя полнофункциональные СУБД.
Предметная область базы данных (ПО) – организация, подразделение, для которого создается БД.
Объект (сущность) – предмет, человек или событие, о котором собирается и храниться информация.
Экземпляр (запись) объекта – единичное значение объекта.
Атрибут – отдельная характеристика (свойство) объекта.
Таблица – совокупность записей с фиксированным числом полей.
Ключ – атрибут или группа атрибутов (называемых ключевыми), однозначно определяющая экземпляры объекта (запись или строку таблицу).
Словарь базы данных – централизованное хранилище сведений об объектах, данных, взаимосвязях, источниках, значениях, формах представления.
Администрация базы данных (АБД) – лицо или группа лиц, ответственная за проектирование и эффективное использование БД.
Основные функции АБД:
Участие в разработке проекта по созданию БД.
Обеспечение целостности БД (копирование, восстановление).
Обучение пользователей работе с БД (вход в БД, ввод паролей, работа в нормальной и экстремальной ситуациях и др.).
Отслеживание графика загрузки БД, сбоев, характеристик (время доступа, общее время обработки запросов и т.д.).
Реорганизация БД с целью улучшения характеристик базы.
Реализация многопользовательского режима работы с БД (парольная защита от несанкционированного доступа, шифрование данных, разделение доступа и др.)
2. Концептуальная, логическая, внутренняя, внешняя модели данных. Формы записи концептуальных моделей. Физическая и логическая зависимость данных.
Выделяют четыре уровня моделей представления данных в базе:
Концептуальная модель (концептуальная схема) – это совокупность объектов и их зависимостей вне зависимости от конкретной СУБД.
Логическая модель (логическая схема) – это концептуальная модель в терминалах конкретной СУБД.
Внутренняя модель (физическая схема, физическая модель) – это представление данных на внешнем носителе.
Подмодель (подсхема, внешняя схема) – это представление о базе с точки зрения пользователя таблицы. Эта модель упрощает для пользователя представление о базе (не нужно знать всю базу, а только ее часть, используемую пользователем) и защищает базу данных от несанкционированного использования данных за пределами внешней модели.
Формы записи концептуальной модели.
Рассмотрим четыре формы записи концептуальной модели.
Овал-диаграммы Бахмана. Наименование каждого объекта заключается в овал, и овалы соединяются линиями связей объектов.
Достоинства: наглядность и компактность.Недостаток: отсутствие атрибутов.
Табличная форма. Объект представляется в виде таблицы: наименование объекта – это наименование таблицы, а наименование атрибутов указываются в ее строках или колонках. Ключевые атрибуты выделяются (обычно подчеркиванием).
Достоинство: детализация.Недостатки: громоздкость при большом числе объектов и трудоемкость.
Списки. Объект представляется в виде списка: наименование объекта является наименованием списка, которое указывается перед списком, а наименование атрибутов указываются через запятую в виде списка, заключенного в круглые скобки. Ключевые атрибуты выделяются.
Достоинства: детализация и меньшая трудоемкость.Недостатки: громоздкость при большом числе объектов и трудоемкость.
ER-диаграммы. Графическое изображение взаимосвязей объектов и их экземпляров в видеER-диаграммы и диаграммER- экземпляров. Для класса обязательного объекта «жирная» точка указывается на линии связи в прямоугольнике, смежном с прямоугольником этого объекта, а для необязательных – вне прямоугольника объекта.
Рис. 1.3.5.2. Диаграмма ER экземпляров
Для класса обязательного объекта “жирная” точка указывается на линии связи в прямоугольнике, смежном с прямоугольником этого объекта (рис. 1.3.5.1), а для необязательных вне прямоугольника объекта.
3. Индексирование таблиц. Определение индекса и его значение. Типы индексов.
Для таблиц создаются индексы (индексированные таблицы). Для некоторых СУБД (FoxPro, dBase,Paradox) индексы могут храниться на диске в отдельных индексных файлах. Индексный файл содержит записи, каждая из которых содержит два значения: индекса и адреса записи таблицы со значением данного индекса. Адреса могут быть абсолютными (номер цилиндра, дорожки, сектора), относительными (номер записи в таблице) или символическими. Записи в индексном файле отсортированы по возрастанию или убыванию значения индекса.
Индексом может быть поле или группа полей (составной индекс) или свертка индекса в виде хеш-кода (шифрованное значение ключа). Хеш-код уменьшает размер индекса, но требуется дополнительное время но шифрование и дешифрование специальными программами (процедурами хеширования или рандомизации). Индексные файлы могут быть многоуровневыми.
Обычно выделяют четыре типа индексов:
Первичный (Primary) который является уникальным, служит для связи с другими таблицами. У таблицы может быть только один первичный индекс. Индексные поля могут иметь пустые значения.
Вторичный иликандидат (Candidat). аналогичный первичному, но не может быть им, так как место первичного индекса уже занято.
Уникальный (Unique) индекс хранит неповторяющиеся значения индекса, т.е. дублирующиеся значения игнорируются.
Регулярный (Regular) индекс хранит значения индексов всех записей таблицы. Обычно такой индекс является внешним ключом.
Наличие индекса позволяет:
обработать таблицу в нужной последовательности (логическая сортировка базы);
осуществить прямой поиск нужной записи по ее индексу путем перебора записей индексного файла и сравнения текущего индекса (свертки) с искомым значением индекса (свертки после ее получения по искомому индексу). После нахождения записи в индексном файле выбирается адрес, и запись таблицы с данным адресом становиться текущей. Если используется свертка, и имеются синонимы, то дополнительно просматривается цепочка синонимов и выбирается запись с искомым значением индекса. Так как размеры индексных файлов небольшие, они хранятся в оперативной памяти, и их просмотр ведется в оперативной памяти очень быстро;
связать родительскую таблицу с дочерней таблицей по индексу;
организовать быстрый последовательный поиск группы записей таблицы по условию их отбора путем использования фильтрованного индекса или использовать индексы вместо полей записей таблицы в условиях отбора записей.
Процессом просмотра и доступа к базе данных управляет только один индексный файл (главный). Однако при изменении информации в таблице обновляются все индексные файлы таблицы. Главный индексный файл можно определить при помощи специальных команд управления индексами (для FoxPro:SetOrder,SetIndex).
4. Связывание таблиц. Назначение, типы связей и средства установки связей.
Таблицы обычно связываются попарно через ключи связи. Ключи связи должны быть одинакового типа в родительской и дочерней таблицах. Связи бывают постоянными и временными. Постоянные связи устанавливаются до выполнения прикладной программы при создании логической модели данных (обычно визуальными средствами). Этими связями можно пользоваться в прикладной программе. Временные связи устанавливаются при выполнении прикладной программы и удаляются после ее выполнения. Использование связанных таблиц существенно упрощает пользовательскую обработку таблиц (так, перемещаясь по родительской таблице, происходит автоматическое перемещение по ее дочерним таблицам по условию равенства ключей связи), автоматически обеспечивая контроль целостности. Дочерняя таблица должна иметь индекс по ключу связи.
Типы связей между объектами.
Тип связи «Один-к-одному», или бинарная связь (1:1). Полями связи являются ключевые поля. Одной записи родительского объекта «А» соответствует только одна запись дочернего объекта «В» и наоборот (A<-->B).
Связь типа «Один-ко-многим» (1:М). Полями связи являются ключевое поле родительского объекта и не ключевое поле дочернего объекта «А» соответствует несколько записей дочернего объекта «В» (A-->>B). Объект «А» называют односвязанным, а «В»- многосвязанным.
Связь типа «Многие-к-одному» (M:1). Полями связи являются не ключевое поле родительского объекта «А» и ключевое поле дочернего объекта «В» (A<=B).
Связь типа «Многие-ко-многим» (M:М). Полями связи являются не ключевые поля родительского и дочернего объектов. Одной записи родительского объекта «А» соответствуют несколько записей дочернего объекта «В» и наоборот (A<=>B).
Типы связи обычно указывают над линией связи между объектами символами «1», «М». Для наглядности связи типа «М» на схеме она может быть указана в виде линии с двумя стрелочками или «гусиной лапкой», а отношение 1 – в виде линии с вертикальной чертой.
Контроль целостности связей осуществляется автоматически СУБД согласно правилами, которые устанавливаются при проектировании БД.
Ввод данных. Если добавляется новая запись в дочерний объект, для которого отсутствует запись из родительского объекта, то такой ввод может быть заблокирован (режимCascade ).
Корректировка данных. Если корректируется поле связи родительского объекта, то автоматически меняются поля связей соответствующих записей дочернего объекта (режимCascade – каскадное обновление), или корректировку нужно заблокировать (режимRestrict ).
Удаление записей. Если удаляется запись родительского объекта, то автоматически удаляются все соответствующие записи дочернего объекта (режимCascade ), или удаление нужно заблокировать.
Основные команды языка запросов SQLс примерами.
Select является мощным средством создания запросов на выборку информации. Приведем ее предварительный Синтаксис:
Рассмотрим фразы команды (не все фразы обязательны).
Select [Distinct ] <выражение> [[As] <псевдоним> ][,…]
From<таблица> [<тип связи>Join<таблица>On<условие связи>]…
Distinct – дублирующие записи запроса не выводятся. Имя поля может быть составным, с включением имени таблицы, точки и самого имени таблицы. Если имя таблицы содержит пробелы, то оно заключается в апострофы. Вместо имени поля можно указать звездочку, если необходимо построить выборку из всех полей таблицы.
Псевдоним – задает наименование колонки (пробелы запрещены). Для связывания таблиц используется фразаJoin. Тип связи задается словами:Left/Right (в запрос входят все записи из таблицы, состоящей в запросе слева/справа),Inner (входят только записи с совпадающими ключами связи).
Пример задания базового запроса по базе строек:
Inner Join “zakazhiki.db” Zakazhiki ON (Stroiki.Kz = Zakazhiki.Kz)
Inner Join “podrjdhiki.db” Podrjdhiki ON (Stroiki.Kp = Podrjdhiki.Kp)
В результате выполнения запроса получается совокупность колонок, в заголовках которых могут находиться имена полей. Если вас не устраивают имена, формируемые по умолчанию, то можно назначить свои (псевдонимы), указав их после слова AS. В выражении могут использоваться специальные арифметические функции, действующие «по вертикали»: среднее значение по группе(Avg), минимальное(Min), максимальное(Max), сумма(Sum), число записей в группе(Count). Функция может иметь в качестве аргумента звездочку(Count(*)), что означает подсчет всех записей, попавших в выборку.
Where <условие отбора> - условие отбора записей в запрос. В условиях допускается использование логических операторовAnd, Or, Not и круглых скобок. В условиях, кроме любых функций Pascal, могут содержаться следующие операторы SQL:
<выражение> Like <шаблон> позволяет построить условие сравнения по шаблону, набор символов: "_" (неопределенный символ), "%" (любые символы, например: Where Ns Like 'Школа%'), [n-k]% (любые символы из интервала от п до k, например: Like '[A-D]%');
<выражение> Between <нижнее значение>And <верхнее значение> проверяет, находится ли выражение в указанном диапазоне (Where [Ss] Between 0 And 1000000);
<выражение> In (<выражение>,<выражение>. ) проверяет, находится ли выражение, стоящее слева от слова IN, среди перечисленных справа от него (Where Kz In (1,2,6)).
Group By <колонка>[,<колонка>. ] - задаются колонки, по которым производится группирование выходных данных. Все записи таблицы, для которых значения колонок совпадают, отображаются в выборке единственной строкой. Группирование удобно для получения некоторых сиодных характеристик (суммы, число записей, среднее) группы.
Пример. Вывести число сотрудников, максимальную, среднюю, минимальную и итоговую зарплату по подразделениям (поле Pord) по таблице SOTRUDNIKI.
Select podr, Count(*),Min (zarpl), Avg (zarpl), Max(zarpl), Sum (/nipl)
From Sotrudniki Group By podr Order By podr
Having <условие отбора группы> задает кртерий отбора сформированных в процессе выборки групп.
Order By <колонка> [Аsc/Desc] [,колонка> [Asc/Dtsc]…] - опция, которая задаст упорядочение по возрастанию (Desc). Колонка задается номером или именем поля (Order By Кр, Kz).
Рассмотрим другие команды SQL.
Create Table <имятаблицы> (<поле> <типполя> [Not Null]. ) - создание таблицы (Create Table Kadr (Tab Integer, Fam Char (30) Not Null Primary Key (Tab))). Обязательное присутствие значения в поле задается параметром Not Null. Основные типы полей в SQL в Delphi: Smalllnt (Short), Integer (Long Integer), Numeric(x,y), Float (x,y), Char (n), Data, Boolean, Time, Money, Autoinc. Для других СУБД типы полей могут быть другими.
Create View <имя представления> [(<имя столбца>. )] As <onepamop Select> - создание представления с новыми именами столбцов (Create View NameStroek As Select Stroiki.Ns FROM Stroiki).
Alter Table <имя таблицы>
Update <таблица> Set <имя поля>=<<новое 3HO4eHue>\Null>. [Where <условие>] - изменение значений полей (Update Kadr Set Oklad=1.5*Oklad Where Сех="Цех N2").
Insert Into<UMH таблицы>(<список полей>)
Insert Into Zakazhiki (Kz.Nz) Values (3,'ЗИЛ1); // включение одной записи Insert Into Podrjdhiki (Kp.Np) Select KPodr, NPodr From SpravPodr Where DSozd >01.01.80; //включение группы записей из таблицы SpravPodr
Create [Unique] Index <имя индекса> On <таблица> (<поле> [
Drop Table/View <имя> - удаление таблицы/представления (Drop Table Stroiki).
Drop Index ["<имя таблицы>".]<имя индекса> - удаление индекса.
Drop Index [“<имя таблицы>".]Primary - удаление главного индекса.
Delete From <имятаблицы> [Where<ycnoeue>] - удаление записей.
В запросе любого типа может быть вложенный запрос, который называется подзапросом. Подзапрос - это запрос, результат которого используется в условии отбора в выражении Where другого внешнего запроса. Подзапрос заключается в круглые скобки.
Пример. Вывести крупные стройки со сметой выше средней по стройкам: Select * From Stroiki Where Ss > (Select Avg(Ss) From Stroiki).
6. Распределенная база данных. Определение, основные термины, типы моделей, достоинства и недостатки.
Распределенная база размещается на различных узлах сети, но, с точки зрения пользователя, база воспринимается как единая локальная БД. Информация обо всех фрагментах находится в глобальном словаре данных. Для обеспечения корректности доступа к данным используется двухфазная фиксация транзакций: на первом этапе производится фиксация транзакций на каждом узле с возможностью отката назад, и при успешном завершении производится необратимая фиксация всех изменений.
Достоинства: пользователи работают с последней версией БД, экономится дисковая память. Недостатки: большие затраты коммуникационных ресурсов (они связываются на время выполнения транзакций) и жесткие требования к надежности и производительности каналов связи.
Принципы и этапы проектирования и создания баз данных.
Основные принципы проектирования баз данных.
1. Удовлетворение информационных потребностей различных пользователей за приемлемое время и в удобном виде.
2. Гибкая и нетрудоемкая модификация при изменении предметной области, программ и технических средств.
3. Достоверность данных, исключение дублирования.
4. Защита от несанкционированного доступа.
5. Восстановление данных и надежность функционирования.
Этапы и шаги проектирования и создания баз данных1. Создание локальной концептуальной модели данных. Построение локальной концептуальной модели данных для каждого типа пользователя предметной области.
1.1 Определение типов сущностей. Выявление основных типов сущностей в представлениях пользователя и их документирование.
1.2. Определение типов связей. Определение типов связей между сущностями; документирование и составление ER-диаграмм.
1.3. Определение атрибутов и их связей. Связывание атрибутов с сущностями; выявление простых, составных, множественных, производных атрибутов и их документирование.
1.4. Определение доменов атрибутов.
1.5. Определение первичных и вторичных ключей.
1.6. Определение суперклассов и подклассов для типов сущностей.
1.7. Создание ER-диаграмм для отдельных пользователей.
1.8. Согласование локальных концептуальных моделей с пользователями. При отрицательных результатах согласования нужно вернуться назад на соответствующий шаг для пере проектирования.
2. Построение локальной логической модели. Построение локальной логической модели для каждого типа пользователя на основе концептуальной модели.
2.1. Выбор целевой СУБД. Формулирование требований и ограничений к СУБД. Изучение и сравнительный анализ СУБД. Оценка кандидатов и выбор СУБД.
2.2. Преобразование локальной концептуальной модели в логическую. Удаление из концептуальной модели связей типа М:М, сложных, рекурсивных и избыточных связей, множественных атрибутов, связей с атрибутами. Перепроверка связей типа 1:1.
2.3. Определение набора отношений. Определение и документирование набора отношений (таблиц) и связей между ними, первичных, вторичных и внешних ключей; форматы представления данных (столбцов) в отношениях.
2.4. Нормализация отношений. Проверка и, при необходимости, проведение процедуры нормализации отношений, по крайней мере, в нормальную форму Бойса-Кодда (НФБК).
2.5. Согласование транзакций с пользователями. Проверить, что локальная логическая модель позволяет выполнить вес транзакции, запросы и отчеты, предусмотренные пользователями. Если это не так, то нужно вернуться назад на соответствующий шаг для пере проектирования.
2.6. Создание ER-диаграмм для отдельных пользователей.
2.7. Определение требований поддержания целостности данных. Определение ограничений, налагаемых на отдельные элементы (поля, строки, таблицы, ключи, индексы, связи), правила обновления данных, бизнес-правила, триггеры. Документирование всех ограничений.
2.8. Согласование локальных логических моделей с пользователями. Убедиться, что локальные логические модели правильно отражают представления пользователей о предметной области. При необходимости нужно вернуться назад (на соответствующий шаг) для пере проектирования.
3. Создание глобальной логической (канонической) модели данных. Объединение локальных логических моделей в единую глобальную логическую модель всей предметной области приложения.
3.1. Объединение локальных логических моделей данных в глобальную логическую модель . Анализ имен и связей сущностей, первичных ключей. Последовательное объединение сущностей и связей из отдельных локальных моделей. Устранение дублирования простых и транзитивных связей между сущностями. Выявление пропущенных сущностей и связей. Проверка корректности внешних ключей, ограничений целостности.Унификация имен и форматов представления данных, связей и других элементов модели. Выполнение чертежа (ER-диаграммы) глобальной логической модели и ее документирование.
3.2. Проверка глобальной логической модели данных. Проверка и, при необходимости, проведение процедуры нормализации отношений. Глобальная логическая модель должна позволять выполнять все транзакции, запросы и отчеты, предусмотренные всеми пользователями. При необходимости нужно вернуться назад на соответствующий шаг.
3.3. Проверка возможностей модификации модели в будущем. Оценка приспособленности модели к возможным изменениям в будущем.
3.4. Создание ER-диаграммы глобальной логической модели.
3.5. Согласование глобальной логической модели с пользователями . Проверка соответствия модели предметной области приложения.
4. Создание глобальной логической модели в среде целевой СУБД.
4.1. Создание таблиц. Создание таблиц, индексов, связей, ограничений, схем (диаграмм), правил, триггеров и других элементов базы данных.
4.2. Реализация бизнес-правил. Правила защиты, контроля, обновления и обработки данных.
5. Проектирование физического представления данных. Определение способов хранения таблиц, строк индексов и других элементов базыданных на магнитных дисках.
5.1. Анализ транзакций. Определение характеристик транзакций (частота выполнения, время доступа к данным и др.).
5.2. Настройка физической среды. Распределение файлов по различным дисководам и таблиц по файлам. Определение первичных и максимально возможных размеров файлов и их приращений. Формирование факторов заполнения страниц данных и индексов. Определение кластерных индексов.
5.3. Определение дополнительных индексов. Введение таких индексов может увеличить производительность системы.
5.4. Анализ введения избыточности данных. Анализ возможности хранения производных данных, дублирования и объединения таблиц на предмет повышения производительности системы.
6. Разработка механизма защиты.
6.1. Разработка представлений (видов) для пользователей.
6.2 Определение прав доступа. Определение прав (полномочий, ролей) для каждого пользователя и его объектов (таблиц, запросов, представлений, колонок и строк и др.).
7. Загрузка информации в базу данных.
7.1. Конвертирование существующих файлов в загрузочные файлы. Если уже существуют файлы с данными, пригодными для загрузки, то разрабатываются программы-конверторы, которые преобразуют эти файлы в файлы, используемые для загрузки в базу данных.
7.2. Загрузка реальной информации в базу данных.
7.3. Сдача системы в эксплуатацию.
8. Настройка функционирования системы и ее модификация.
8.1. Настройка функционирования системы. Сбор и обработка статистической информации об эффективности функционирования системы и ее настройка с целью повышения производительности работы системы.
8.2. Модификация системы. Внесение изменений в систему с целью устранения выявленных ошибок, связанных с изменениями в предметной области.
8. Нормализация отношений с примерами.
Метод нормализации отношения (таблицы) - это процесс постепенного улучшения отношения (таблицы) путем последовательного перевода отношения (таблицы) из ненормализованной формы в первую, во вторую, в третью (иногда в четвертую и пятую) нормальные формы.
Проектирование таблиц можно начинать с построения концептуальной модели и определения состава атрибутов для каждого объекта. Затем все атрибуты можно объединить в одну исходную таблицу. Можно сразу, без построения концептуальной модели, сформировать исходную таблицу.